Why we built OpsFabric
January 15, 2026 · 4 min read · Vedran Lebo
I've spent the better part of fifteen years inside infrastructure that most people never think about.
Not the glamorous kind. Not the "we're running 10,000 Kubernetes pods" kind. The kind that keeps production servers patched, configurations consistent, and compliance audits passing. The kind that quietly ensures hundreds of Linux machines are running the right software, at the right version, without anyone noticing.
That work taught me something that took years to fully articulate: the hardest part of infrastructure operations is not doing the thing. It's knowing what to do, and to what, and proving you did it.
The problem I kept running into
Whether I was managing Linux fleets for various clients, running SRE engagements for enterprise teams, or helping smaller shops get their infrastructure under control, the same problems appeared, over and over.
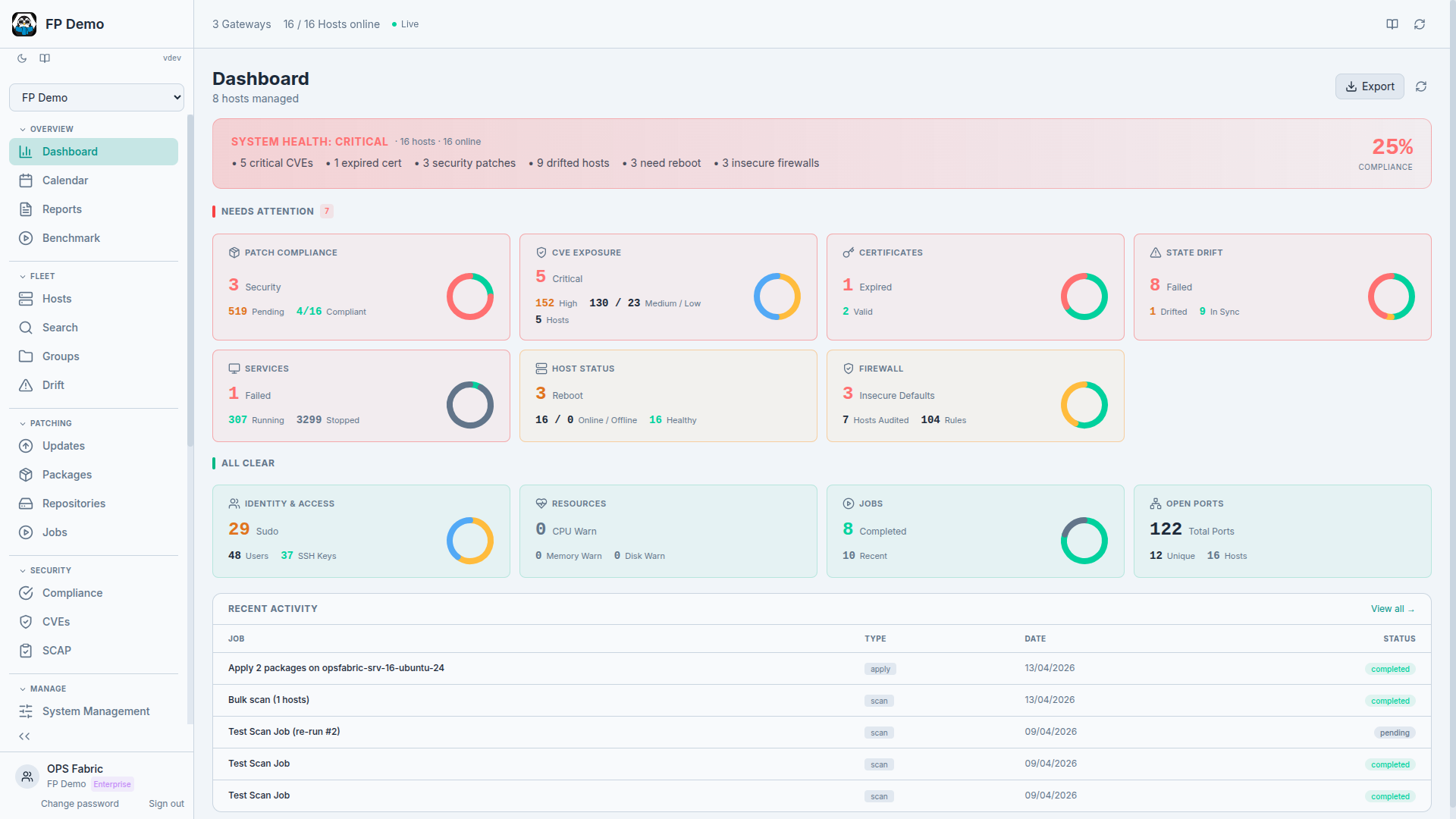
Teams had tools. They had configuration management, or a mix of automation and scripts. They had cloud consoles and CMDBs and spreadsheets. What they didn't have was a coherent picture of their fleet. Not in real time, not historically, and certainly not in a form that was useful when an auditor or a security team asked a pointed question.
Patching was the worst example. Everyone knew patching mattered. CVEs were tracked, policies were written, escalations were documented. But when you asked "which of our 400 Linux hosts are currently vulnerable to this CVE", the honest answer, in most teams, was "we're not entirely sure, let us run some queries and get back to you."
That's not a tooling gap. That's a model gap. The tools existed. The data existed. It just wasn't connected in a way that made the fleet legible.
Why existing tools didn't solve it
The commercial RMM market is dominated by tools built for Windows-first MSP environments. Automox, NinjaOne, Action1. They're well-built products, but they carry the assumptions of that world. Linux support is an afterthought. The data model is shallow. The agent is a black box. And the pricing is built for a reseller margin structure that doesn't make sense for direct enterprise use.
On the other side, you have the DIY path. Configuration management tools, custom scripts, home-built dashboards. This works if you have the engineering capacity to build and maintain it, but it means reinventing the same wheel every engagement, every client, every time.
There was no serious Linux-native fleet operations platform that treated the fleet as a data problem. So we built one.
Why open source
When we decided to build OpsFabric, the choice of foundation mattered enormously. We needed an agent that was open source, auditable, and production-hardened, not a proprietary black box controlled by a vendor whose roadmap might diverge from ours.
The foundation we chose gives us structured, continuously available node facts. A fast, async execution engine designed for scale. A real-time event bus that streams results as each host completes. And an open source license that means the agent running on your nodes is inspectable, not opaque.
This also happens to be technology I've used for years across real production environments. I know where it's strong and where it needs a good platform layer on top of it. OpsFabric is, in part, that layer.
What we're building
OpsFabric is a Linux patch management and infrastructure operations platform. But the more precise description is this: it's an infrastructure data engine with a management layer on top.
Your fleet reports its state on demand. Every patch job, every configuration change, every sync. Recorded, structured, queryable. Fleet Search lets you query your infrastructure with structured filters and get answers backed by live data. CVE intelligence maps your installed packages to known vulnerabilities. SCAP compliance scans validate against CIS, STIG, PCI-DSS, and other benchmarks. Compliance reporting is derived from the data, not assembled manually.
But OpsFabric doesn't stop at observation. State Profiles let you declare what should be true (which users should exist, which services should be running, which firewall rules should be enforced, which kernel parameters should be set) and the platform enforces it across your fleet. Dry runs let you preview changes safely. Drift detection tells you when reality diverges from intent.
The goal is simple: make your fleet legible. Make it auditable. Make the gap between "what should be true" and "what is actually true" visible and closable. Then close it.
We're building this for the teams I spent fifteen years working alongside. The ones who know their infrastructure is complex, who take patching and compliance seriously, and who are tired of duct-taping four different tools together to get a basic answer about their own fleet.
Next in the series: What is infrastructure as data?: the model that makes the fleet legible, queryable, and enforceable.