What is infrastructure as data?
January 28, 2026 · 5 min read · Vedran Lebo
Infrastructure as Code was a genuine leap forward. Defining systems declaratively, versioning them in git, applying them reproducibly. These ideas transformed how teams manage infrastructure at scale.
But IaC has a blind spot that becomes obvious the moment you're operating a real fleet under real pressure: it describes what you want, not what you have.
Your Terraform state is a snapshot, not a live record. Your Ansible playbooks define intent, not reality. Your CMDB, if you have one, is almost certainly out of date. The gap between declared state and actual state is where incidents live, where compliance findings hide, and where on-call engineers spend their most stressful hours.
Infrastructure as Data is the next step. Not a replacement for IaC, but a complementary model that makes the fleet itself legible. Continuously, structurally, and queryably.
The three pillars
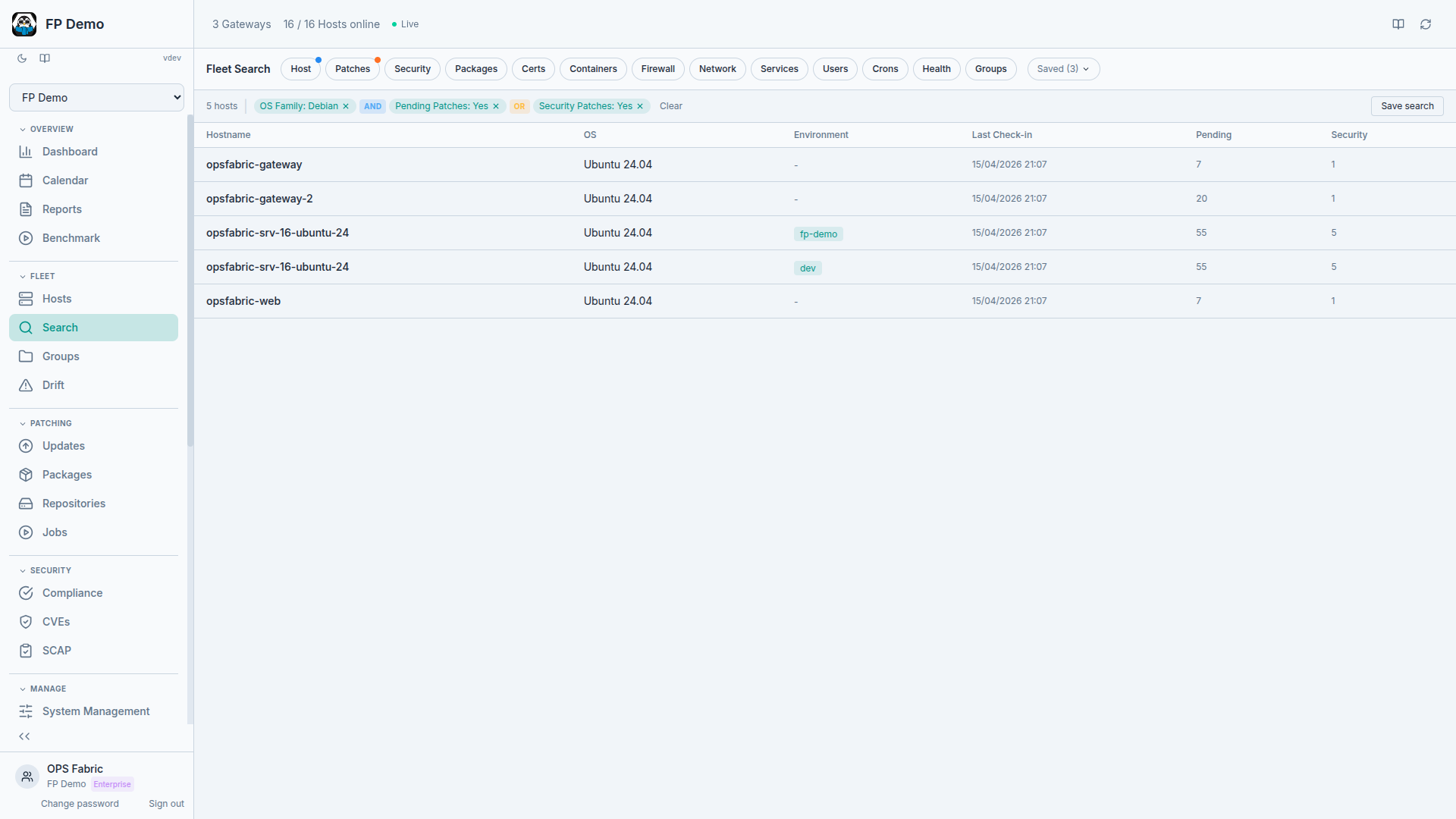
Unified fleet state
Every node in your fleet, whether cloud VM, bare metal server, or edge device, reports its actual state on demand. OS version, kernel, installed packages, running services, applied configuration, hardware profile. This isn't a quarterly snapshot assembled under pressure. It's a structured record, updated whenever you sync a host, run a scan, or take an action.
The result is a fleet dataset that reflects reality, not intent.
Queryable, not just observable
Most monitoring and observability tools let you watch your infrastructure. Infrastructure as Data lets you interrogate it.
Which nodes are running a kernel older than 5.15? Which hosts haven't received a patch in 60 days? Which services are listening on unexpected ports? Which machines are missing a required package? These are data queries, and they should return answers in seconds, against live data, without requiring an engineer to write custom inventory scripts.
Action as a write operation
When you patch a node, enforce a firewall baseline, deploy a user account, or tune kernel parameters, that action is a write to the infrastructure dataset. The system records what changed, on which node, when, and by whom. Rollback becomes a revert. Auditing becomes a query. Compliance evidence becomes a report derived from the record, not a document assembled manually.
Why this matters in practice
Consider a concrete scenario: a critical CVE drops affecting OpenSSL versions below 3.0.8. You need to know which hosts are affected, right now, before the security team asks.
In a traditional setup, this means writing a config management query, or an inventory filter, or firing a command across your fleet, all requiring you to know the exact query syntax, the inventory format, the right tool for the job. Even for experienced engineers, this takes meaningful time and context-switching.
In the Infrastructure as Data model, this is a query:
hosts where package:openssl < 3.0.8
The answer comes back in seconds. Then you act: create a patch job targeting exactly that cohort, schedule it, track remediation, close the loop.
The difference isn't automation. You had automation before. The difference is operational clarity. The fleet can answer questions about itself.
Compliance as a query
The compliance implications of this model are significant.
Traditional compliance workflows are built around snapshots: quarterly scans, annual audits, point-in-time reports. The gap between the snapshot and reality is where findings accumulate and where auditors find surprises.
When infrastructure state is continuously captured and indexed, compliance becomes continuous too. The data is always there because it's always being recorded.
Your SOC 2 auditor wants to know which hosts had unpatched critical CVEs in Q3? That's a query over a time-series dataset. Your security team needs evidence that a specific remediation was applied within the required SLA? That's an audit log derived from infrastructure writes. Your DORA compliance review needs proof that change management procedures were followed? The record exists because every action was recorded when it happened.
Compliance artifacts stop being documents you produce under pressure. They become queries you run against data that already exists.
The ops intelligence layer
There's a further benefit that becomes available once you have a structured, historical dataset of your fleet: pattern recognition at scale.
Which nodes are consistently drifting from their desired state? Which patch jobs are repeatedly failing on a specific OS family? Which configuration changes correlate with increased service restarts? Which hosts have the most frequent state violations?
These questions today require custom dashboards, log correlation, and significant manual effort. In the Infrastructure as Data model, they're queries, and increasingly, they're questions you can ask in natural language, backed by real operational data.
This is where AI becomes genuinely useful in an ops context: not as a chatbot, but as a natural language query interface to a structured fleet dataset. The data model makes it possible. The AI makes it accessible.
What this looks like in OpsFabric
OpsFabric is built around this model from the ground up.
Per-node facts are collected on demand. Execution results stream back through the event bus to the backend, where they're normalized and stored. Fleet Search exposes the dataset as a queryable interface, with structured queries today and natural language queries on the roadmap. Every patch job, every config change, every action taken through OpsFabric becomes part of the record.
And the data model doesn't just support observation. It supports management. State Profiles let you declare the desired state of your fleet across users, services, packages, firewall rules, cron jobs, and kernel parameters. Dry runs preview what would change. Drift detection shows where reality has diverged. The same data layer that makes your fleet queryable also makes it enforceable.
The fleet knows itself. Your job is to ask it the right questions. And when the answers aren't what they should be, fix them.
Next in the series: How OpsFabric works: what it collects, how fast, and why the numbers matter.